Listening for orcas with an LSTM

After completing a course on deep learning I was anxious to find a data set to try out for my first project. Recently Open AI demonstrated that sentiment could be detected by training a recurrent neural network (RNN) to make letter by letter predictions in a set of Amazon reviews. The amazing thing about the research was that a single “neuron” was able to predict sentiment even though the model was trained on a data set that wasn’t labeled. There’s also a great blog post from Andrej Karpathy that looks at the internals of RNNs and shows how different neurons fire character by character.
Another paper came out around the same time about WaveNet where the authors were able to train a network on a combination of conditioning and raw audio data to create state of the art speech synthesis. That network used a CNN based architecture, but similar results were produced from RNNs in a project called Sample RNN.
I wanted to try running raw audio data through an RNN and see if the outputs were able to detect the presence of marine mammals. For a long time I was stuck trying to find a suitable data set until I found Orchive, a huge set of raw audio recordings of orca whales.
The Data Set
Orchive is a staggering set of raw audio data. The total data set is over 20,000 hours collected over a period of 36 years. The recordings are in mp3 format converted from audio tapes. The tapes were recorded from two sites when orcas were present, with researcher’s voices also included at times giving context about when the tapes were turned on.
I scraped 200 mp3s from the website, all recorded in 2006. The mp3s were converted to single track wav files to simplify the training process. Each recording is about 55 minutes. Note that this is less than 1% of the total data set but still much more than could practically train an LSTM one sample at a time with my hardware (a single GTX 1080).
Design
The network feeds a window of 16 raw audio samples into an LSTM. The LSTM output is stacked with the raw audio and fed into two fully connected layers. The final output is 128 logits that are compared to the mu law encoded next sample as recommended in the WaveNet paper so training can be done via softmax cross entropy.
Training
For training, 128 of the 200 recordings were chosen at random. Ten second samples were then chosen randomly from within those recordings and fed in mini-batches of size 32 for truncated back propagation through time (TBPTT). For this unsupervised learning no validation or test set was used, the network was just repeatedly fed training data till the loss stabilized.
For a baseline, the LSTM was omitted and only two fully connected layers were used. This baseline was used to ensure that the LSTM was participating in the network.
Results
The results were decent. There was one particular output that from visual inspection correlated strongly with orca whistles. Other outputs also showed a shakier correlation with whistles. It is possible with more iterations and a better understanding of the data there could be outputs that predict different types of whistles but probably that is the limit of what an RNN can achieve in this architecture. Most of the outputs fluctuated wildly, results consistent with the ballpark 5% “interesting and interpretable” estimate mentioned by Karpathy.
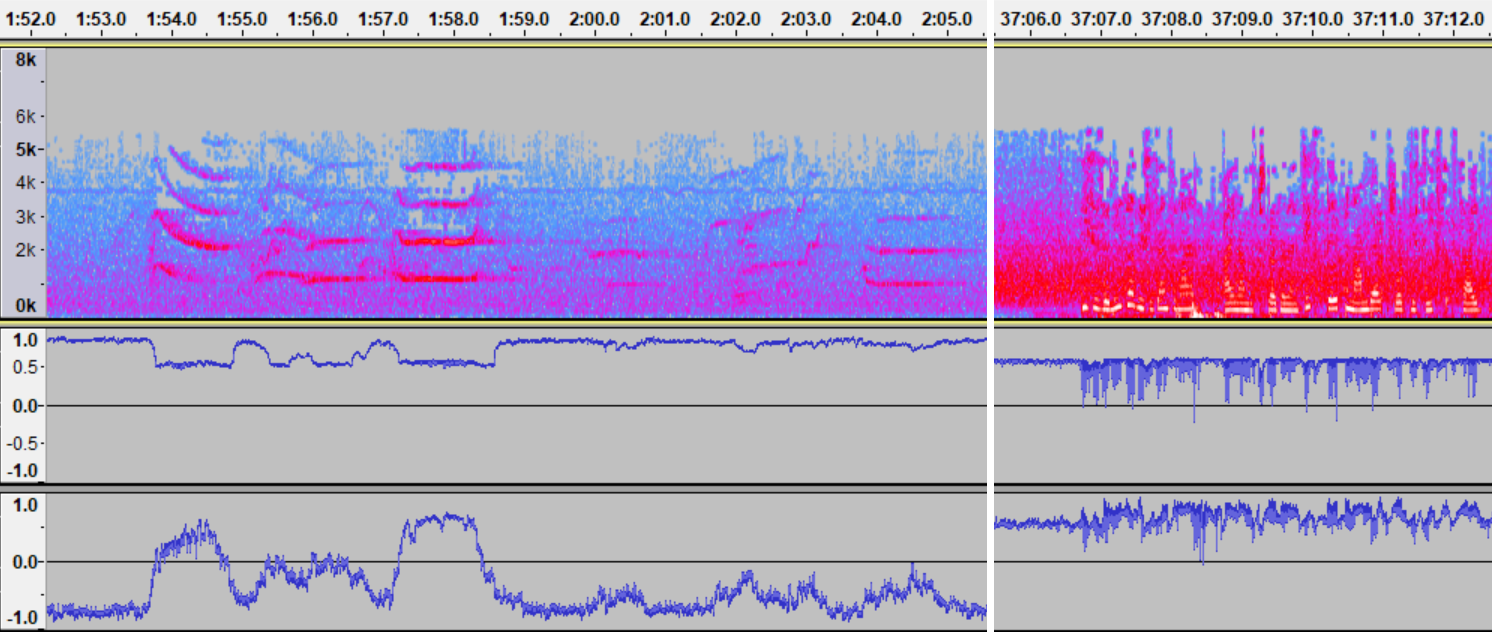
On the top left is a spectrogram of orca whistles; on the top right is a spectrogram of human speech. Below each spectrogram are some interesting outputs from the LSTM. The first output strongly correlates with orca whistles. Notice that it misses some whistles that are picked up by another output, but that output is less stable. Human speech causes the network to go all over the place, but note that the outputs stay in a different range compared to when they are activated by whistles.
Next Steps
There is definitely potential to improve this model. I spent about a week tuning hyper-parameters but never got to more than 256 hidden cells in the LSTM. With more tuning and experimentation a better model could be created, but ultimately this is just a toy project so I’m going to move on to a new architecture. In practice because this model runs one sample at a time every extra hidden state increases the volume of data to analyze, so instead of one wav file to look at a 256 state LSTM create 256 times as much data.
I’m going to try a new model that will allow the RNN to have a stronger abstraction. Instead of working on raw audio, the next model will feed a spectrogram into a GAN with an RNN acting as a sort of embedding for a CNN based generator/discriminator.
References
- Unsupervised Sentiment Neuron - Open AI project that found a sentiment “neuron” in an RNN.
- The Unreasonable Effectiveness of Recurrent Neural Networks Andrej Karpathy’s post with great visualizations of the internals of RNNs.
- WaveNet - State of the art voice results and nice music made by processing raw audio.
- Sample RNN - Similar results to WaveNet using RNNs.
- Orchive - Huge data set of raw audio recordings from orca whales.